 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQualitative Analysis of Correspondence for Experimental Algorithmics
Apr 26, 2002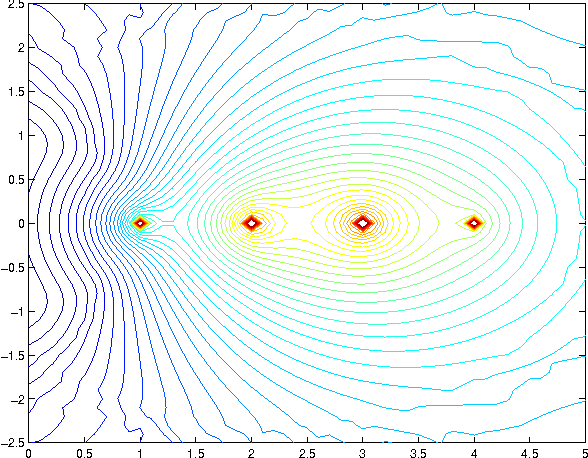

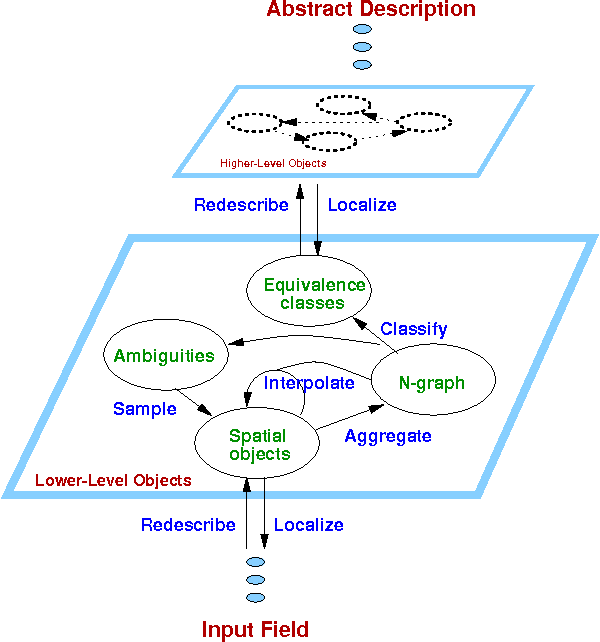

Correspondence identifies relationships among objects via similarities among their components; it is ubiquitous in the analysis of spatial datasets, including images, weather maps, and computational simulations. This paper develops a novel multi-level mechanism for qualitative analysis of correspondence. Operators leverage domain knowledge to establish correspondence, evaluate implications for model selection, and leverage identified weaknesses to focus additional data collection. The utility of the mechanism is demonstrated in two applications from experimental algorithmics -- matrix spectral portrait analysis and graphical assessment of Jordan forms of matrices. Results show that the mechanism efficiently samples computational experiments and successfully uncovers high-level problem properties. It overcomes noise and data sparsity by leveraging domain knowledge to detect mutually reinforcing interpretations of spatial data.
Sampling Strategies for Mining in Data-Scarce Domains
Apr 22, 2002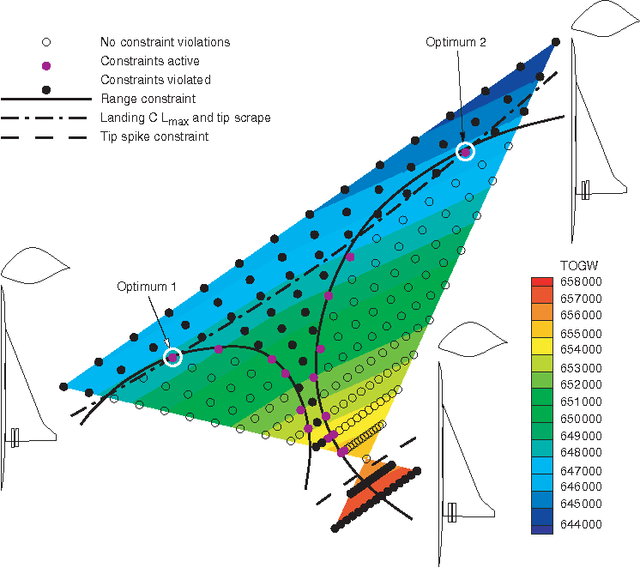
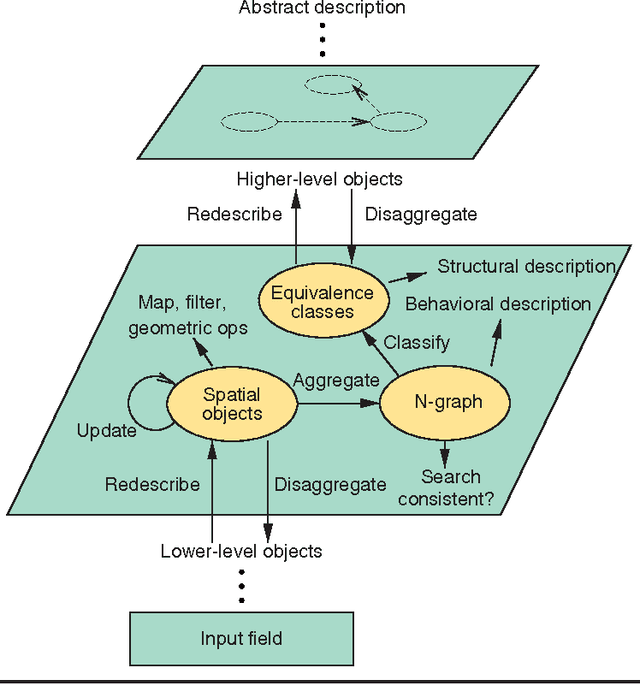
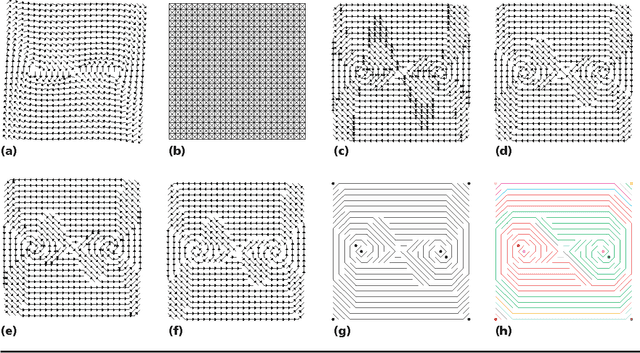
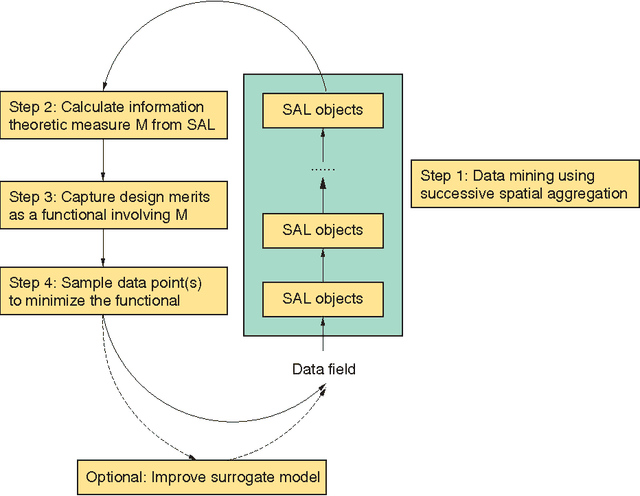
Data mining has traditionally focused on the task of drawing inferences from large datasets. However, many scientific and engineering domains, such as fluid dynamics and aircraft design, are characterized by scarce data, due to the expense and complexity of associated experiments and simulations. In such data-scarce domains, it is advantageous to focus the data collection effort on only those regions deemed most important to support a particular data mining objective. This paper describes a mechanism that interleaves bottom-up data mining, to uncover multi-level structures in spatial data, with top-down sampling, to clarify difficult decisions in the mining process. The mechanism exploits relevant physical properties, such as continuity, correspondence, and locality, in a unified framework. This leads to effective mining and sampling decisions that are explainable in terms of domain knowledge and data characteristics. This approach is demonstrated in two diverse applications -- mining pockets in spatial data, and qualitative determination of Jordan forms of matrices.